Tercera nacionalización
Tercera Forma Normal Una tabla está normalizada en esta forma si todas las columnas que no son llave son funcional mente dependientes por completo de la llave primaria y no hay dependencias transitivas. Comentamos anteriormente que una dependencia transitiva es aquella en la cual existen columnas que no son llave que dependen de otras columnas que tampoco son llave. Cuando las tablas están en la Tercera Forma Normal se previenen errores de lógica cuando se insertan o borran registros. Cada columna en una tabla está identificada de manera única por la llave primaria, y no deben haber datos repetidos. Esto provee un esquema limpio y elegante, que es fácil de trabajar y expandir. Un dato sin normalizar no cumple con ninguna regla de nacionalización. Para explicar con un ejemplo en que consiste cada una de las reglas, vamos a considerar los datos de la siguiente tabla.





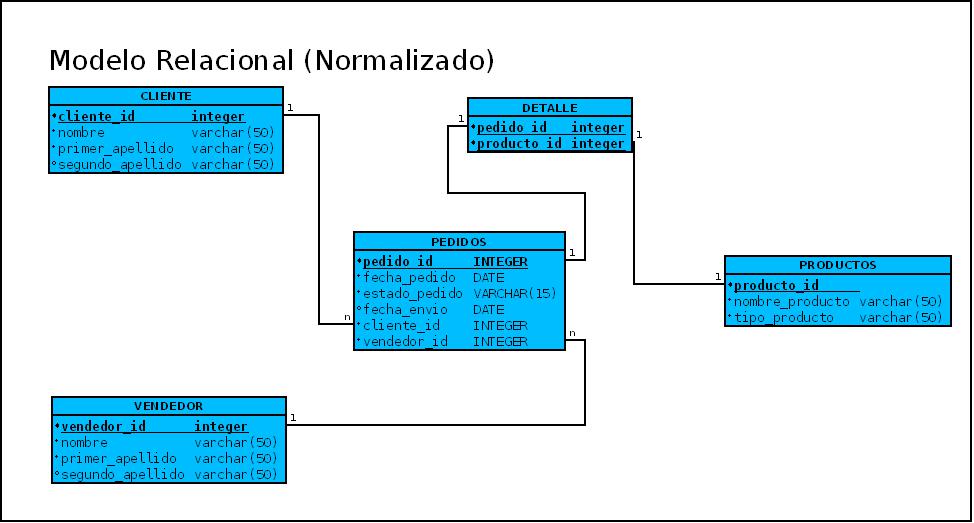



























 .
.

